一、介绍 MQ的消息可靠性,将从以下四个方面展开并实践:
生产者消息确认
消息持久化
消费者消息确认
消费失败重试机制
二、生产者消息确认 对于publisher,如果message到达exchange与否,rabbitmq提供publiser-comfirm机制,如果message达到exchange但是是否到达queue,rabbitmq提供publisher-return机制。这两种机制在代码中都可以通过配置来自定义实现。
以下操作都在publisher服务方完成。
1. 引入依赖 language-xml 1 2 3 4 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-amqp</artifactId> </dependency>
language-yaml 1 2 3 4 5 6 spring: rabbitmq: publisher-confirm-type: correlated publisher-returns: true template: mandatory: true
配置说明:publish-confirm-type:开启publisher-confirm,这里支持两种类型:
simple:同步等待confirm结果,直到超时correlated:异步回调,定义ConfirmCallback,MQ返回结果时会回调这个ConfirmCallback
publish-returns:开启publish-return功能,同样是基于callback机制,不过是定义ReturnCallbacktemplate.mandatory:定义消息路由失败时的策略。true,则调用ReturnCallback; false,则直接丢弃消息
2. 配置ReturnCallBack 每个RabbitTemplate只能配置一个ReturnCallBack,所以直接给IoC里面的RabbitTemplate配上,所有人都统一用。ApplicationContextAware 接口,在接口中setReturnCallback。
language-java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @Slf4j @Configuration public class CommonConfig implements ApplicationContextAware { @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { RabbitTemplate rabbitTemplate = applicationContext.getBean(RabbitTemplate.class); rabbitTemplate.setReturnCallback((message, replyCode, replyText, exchange, routingKey)->{ //check if is delay message if (message.getMessageProperties().getReceivedDelay() != null && message.getMessageProperties().getReceivedDelay() > 0) { return; } log.error("消息发送到queue失败,replyCode={}, reason={}, exchange={}, routeKey={}, message={}", replyCode, replyText, exchange, routingKey, message.toString()); }); } }
3. 配置ConfirmCallBack ConfirmCallBack在message发送时配置,每个message都可以有自己的ConfirmCallBack。
language-java 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Test public void testSendMessage2SimpleQueue() throws InterruptedException { String message = "hello, spring amqp!"; // confirm callback CorrelationData correlationData = new CorrelationData(UUID.randomUUID().toString()); correlationData.getFuture().addCallback( result -> { if (result.isAck()){ log.debug("消息到exchange成功, id={}", correlationData.getId()); }else { log.error("消息到exchange失败, id={}", correlationData.getId()); } }, throwable -> { log.error("消息发送失败", throwable); } ); rabbitTemplate.convertAndSend("amq.topic", "simple.test", message, correlationData); }
4. 测试 将消息发送到一个不存在的exchange,模拟消息达到exchange失败,触发ConfirmCallBack,日志如下。
language-txt 1 2 18:22:03:913 ERROR 23232 --- [ 127.0.0.1:5672] o.s.a.r.c.CachingConnectionFactory : Channel shutdown: channel error; protocol method: #method<channel.close>(reply-code=404, reply-text=NOT_FOUND - no exchange 'aamq.topic' in vhost '/', class-id=60, method-id=40) 18:22:03:915 ERROR 23232 --- [nectionFactory1] cn.itcast.mq.spring.SpringAmqpTest : 消息到exchange失败, id=0c0910a3-7937-43ea-9606-e5bbcdda0b5c
将消息发送到一个存在的exchange,但routekey异常,模拟消息到达exchange但没有到达queue,触发ConfirmCallBack和ReturnCallBack,日志如下。
language-txt 1 2 3 18:27:22:757 INFO 20184 --- [ main] o.s.a.r.c.CachingConnectionFactory : Created new connection: rabbitConnectionFactory#7428de63:0/SimpleConnection@6d60899e [delegate=amqp://rabbitmq@127.0.0.1:5672/, localPort= 53662] 18:27:22:797 DEBUG 20184 --- [ 127.0.0.1:5672] cn.itcast.mq.spring.SpringAmqpTest : 消息到exchange成功, id=5fbdaaa1-5f20-4683-bdfa-bd71cd6afd11 18:27:22:796 ERROR 20184 --- [nectionFactory1] cn.itcast.mq.config.CommonConfig : 消息发送到queue失败,replyCode=312, reason=NO_ROUTE, exchange=amq.topic, routeKey=simplee.test, message=(Body:'hello, spring amqp!' MessageProperties [headers={spring_returned_message_correlation=5fbdaaa1-5f20-4683-bdfa-bd71cd6afd11}, contentType=text/plain, contentEncoding=UTF-8, contentLength=0, receivedDeliveryMode=PERSISTENT, priority=0, deliveryTag=0])
三、消息持久化
新版本的SpringAMQP默认开启持久化。RabbitMQ本身并不默认开启持久化。
队列持久化,通过QueueBuilder构建持久化队列,比如
language-java 1 2 3 4 5 6 7 @Bean public Queue simpleQueue(){ return QueueBuilder .durable("simple.queue") .build(); }
消息持久化,在发送时可以设置,比如
language-java 1 2 3 4 5 6 7 8 @Test public void testDurableMessage(){ Message message = MessageBuilder.withBody("hello springcloud".getBytes(StandardCharsets.UTF_8)) .setDeliveryMode(MessageDeliveryMode.PERSISTENT) .build(); rabbitTemplate.convertAndSend("simple.queue", message); }
四、消费者消息确认 消费者消息确认是指,consumer收到消息后会给rabbitmq发送回执来确认消息接收状况。
SpringAMQP允许配置三种确认模式:
manual:手动ack,需要在业务代码结束后,调用api发送ack。auto:自动ack,由spring监测listener代码是否出现异常,没有异常则返回ack;抛出异常则返回nacknone:关闭ack, MQ假定消费者获取消息后会成功处理,因此消息投递后立即被删除
language-yaml 1 2 3 4 5 6 spring: rabbitmq: listener: simple: prefetch: 1 acknowledge-mode: auto # manual auto none
但是auto有个很大的缺陷,因为rabbitmq会自动不断给有问题的listen反复投递消息,导致不断报错,所以建议使用下一章的操作。
五、消费失败重试机制 当消费者出现异常后,消息会不断requeue (重新入队)到队列,再重新发送给消费者,然后再次异常,再次requeuemq的消息处理飙升,带来不必要的压力。
我们可以利用Spring的retry机制,在消费者出现异常时利用本地重试,而不是无限制的requeue到mq队列。
1. 引入依赖 language-yml 1 2 3 4 5 6 7 8 9 10 11 spring: rabbitmq: listener: simple: prefetch: 1 retry: enabled: true # 开启消费者失败重试 initial-interval: 1000 #初识的失败等待时长为1秒 multiplier: 2 # 下次失败的等待时长倍数,下次等待时长 = multiplier * last-interval max-attempts: 3 # 最大重试次数 stateless: true # true无状态;false有状态。如果业务中包含事务,这里改为false
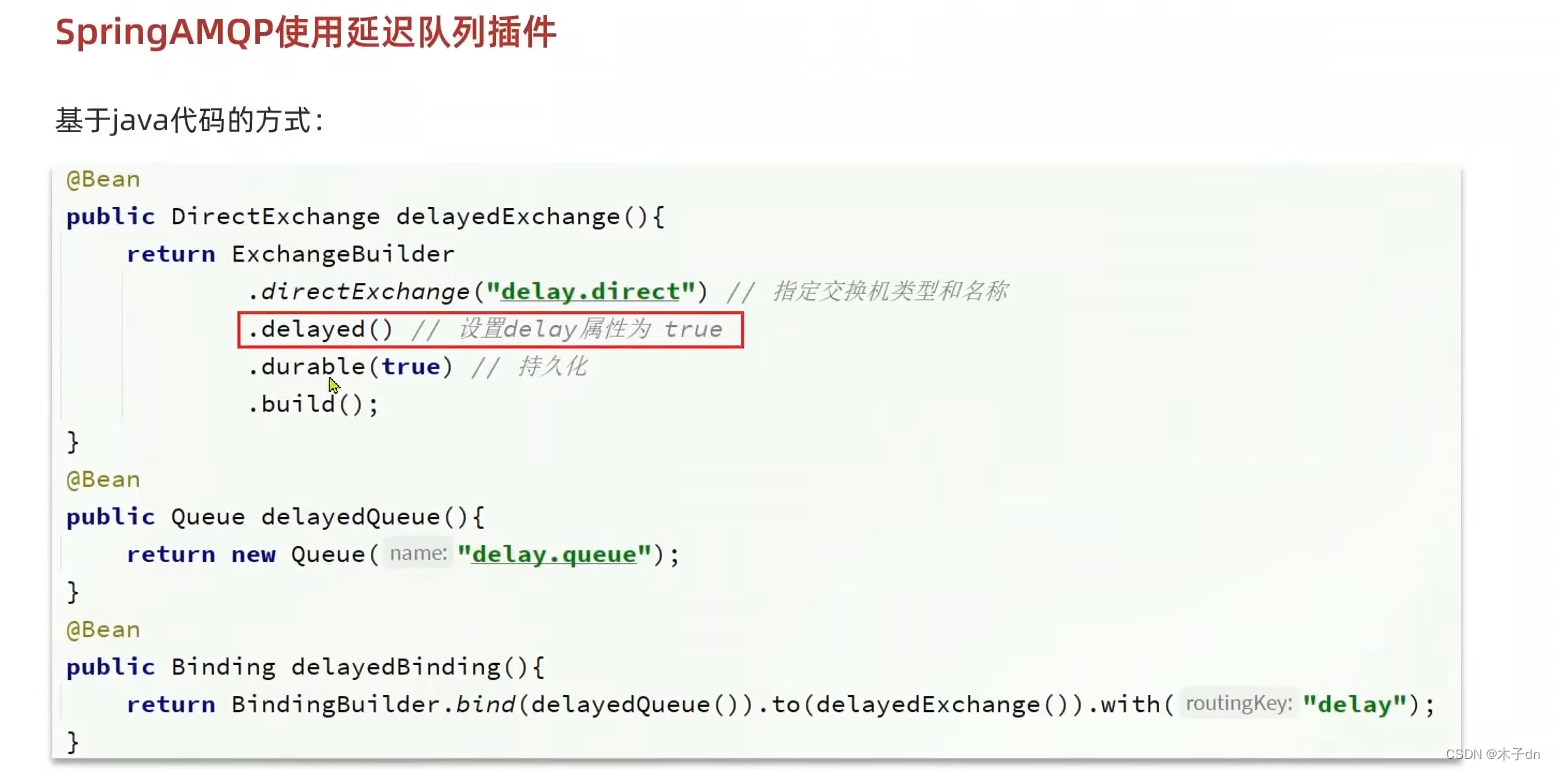
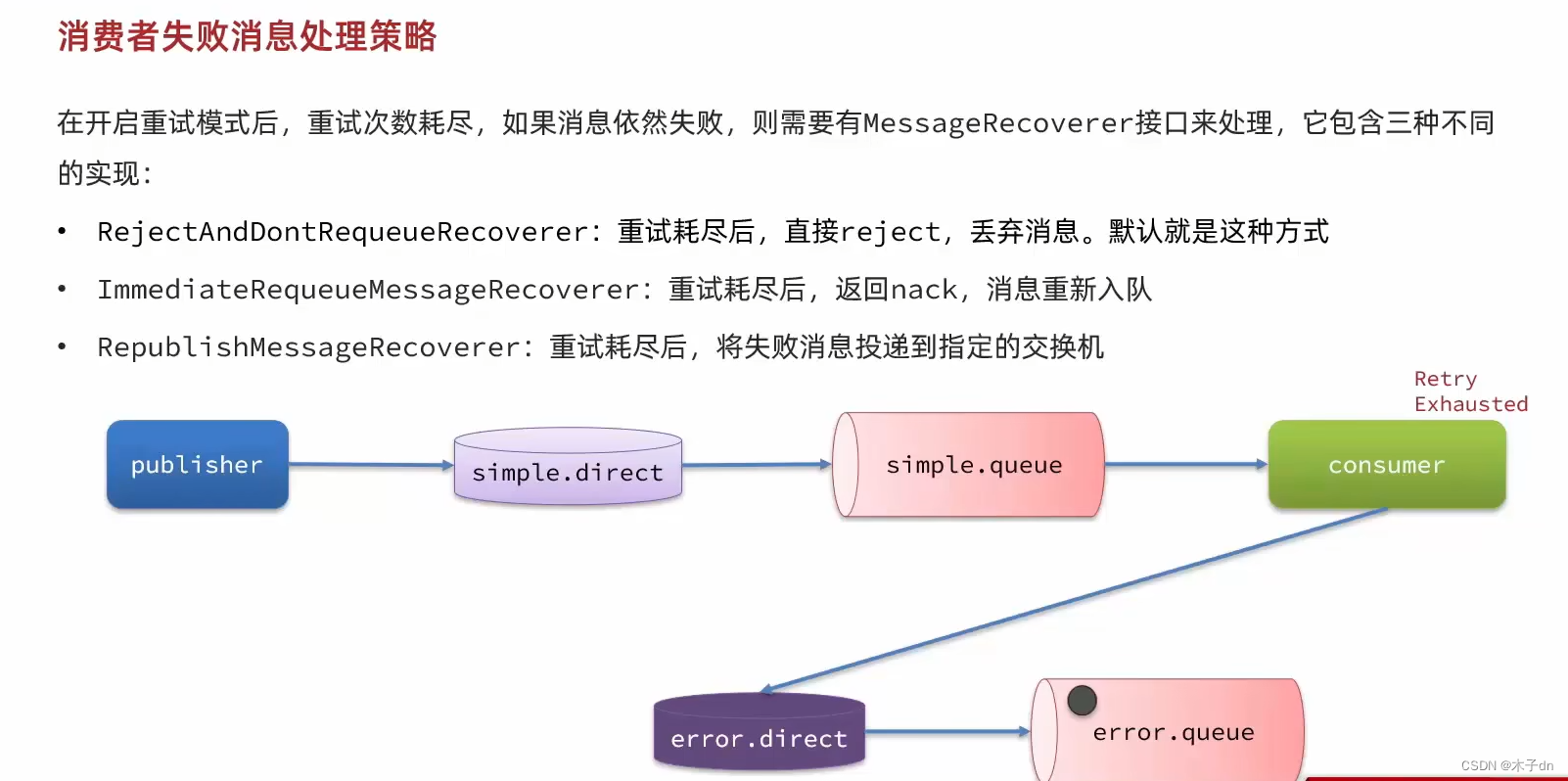
2. 配置重试次数耗尽策略 我们采用RepublishMessageRecoverer。exchange,queue以及它们之间的bindings。
然后定义MessageRecoverer,比如
language-java 1 2 3 4 5 6 7 8 9 @Component public class ErrorMessageConfig { @Bean public MessageRecoverer republishMessageRecover(RabbitTemplate rabbitTemplate){ return new RepublishMessageRecoverer(rabbitTemplate, "error.exchange", "error"); } }
3. 测试 定义处理异常消息的exchange和queue,比如
language-java 1 2 3 4 5 6 7 8 9 @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "error.queue"), exchange = @Exchange(name = "error.exchange"), key = "error" )) public void listenErrorQueue(String msg){ log.info("消费者接收到error.queue的消息:【" + msg + "】"); }
定义如下一个listener,来模拟consumer处理消息失败触发消息重试。
language-java 1 2 3 4 5 6 7 8 9 10 11 @RabbitListener(bindings = @QueueBinding( value = @Queue(name = "simple.queue"), exchange = @Exchange(name = "simple.exchange"), key = "simple" )) public void listenSimpleQueue(String msg) { log.info("消费者接收到simple.queue的消息:【" + msg + "】"); System.out.println(1/0); log.info("consumer handle message success"); }
写一个简单的测试,往simple.exchange发送消息,比如
language-java 1 2 3 4 5 6 @Test public void testSendMessageSimpleQueue() throws InterruptedException { String message = "hello, spring amqp!"; rabbitTemplate.convertAndSend("simple.exchange", "simple", message); }
运行测试,consumer得到以下日志
language-txt 1 2 3 4 5 18:51:10:164 INFO 24072 --- [ntContainer#0-1] c.i.mq.listener.SpringRabbitListener : 消费者接收到simple.queue的消息:【hello, spring amqp!】 18:51:11:167 INFO 24072 --- [ntContainer#0-1] c.i.mq.listener.SpringRabbitListener : 消费者接收到simple.queue的消息:【hello, spring amqp!】 18:51:13:168 INFO 24072 --- [ntContainer#0-1] c.i.mq.listener.SpringRabbitListener : 消费者接收到simple.queue的消息:【hello, spring amqp!】 18:51:13:176 WARN 24072 --- [ntContainer#0-1] o.s.a.r.retry.RepublishMessageRecoverer : Republishing failed message to exchange 'error.exchange' with routing key error 18:51:13:181 INFO 24072 --- [ntContainer#1-1] c.i.mq.listener.SpringRabbitListener : 消费者接收到error.queue的消息:【hello, spring amqp!】
可以看到spring尝试2次重发,一共3次,第一次间隔1秒,第二次间隔2秒,重试次数耗尽,消息被consumer传入error.exchange,注意,是consumer传的,不是simple.queue。