Java基础集合分为两大类,Collection和Map,前者单列集合,后者双列集合。
Collection 下图为Collection集合体系树
Collection下有List和Set两小类集合,List和Set都只是接口。
List的具体实现有ArrayList和LinkedList,Set的具体实现有HashSet,LinkedHashSet,TreeSet。
它们的特点如下表
|——|—————|————|
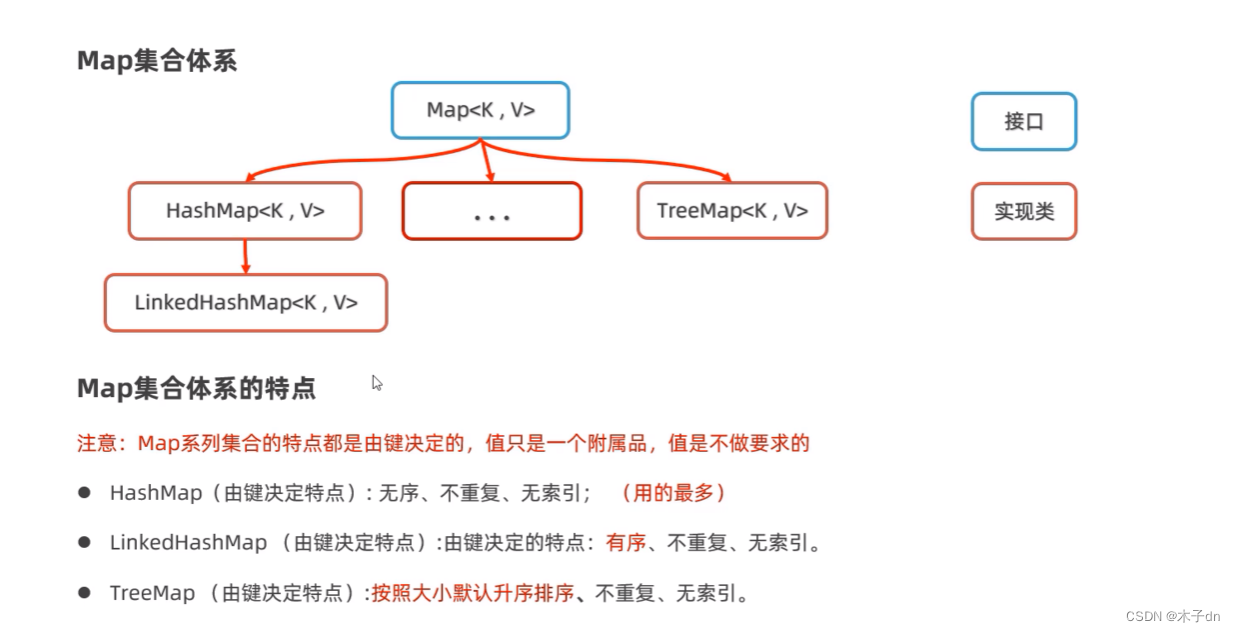
Map 下图为Map集合体系树
其中具体的实现分别是HashMap,LinkedHashMap,TreeMap,特点如下表
|—–|—————|————|
需要注意的是Map的”序”都是基于Key的
性能 ArrayList ArrayList行为和数组无异,插入删除会设计复制覆盖,性能不高,但是因为索引所以涉及索引的操作性能格外的好,比如读取,末尾增删改。同时内存占用很小,除了数据本身没有太多其他的东西。
LinkedList LinkedList在ArrayList基础上,使用”链”链接前后元素,取缔了ArrayList因为复制覆盖造成的低效行为,在增删改性能都很好,但是因为使用了链所以数据在内存中不是连续的,故而失去了索引一步读取的优势,需要遍历才能锁定元素,因此涉及索引的操作都受到一定性能下滑。内存占用比ArrayList多了”链”。
请使用Iterator迭代器,通过Iterator迭代List永远是效率最高的
1 2 3 List<String> list = new ArrayList <String>(); list = new LinkedList <String>();
HashSet HashSet是基于哈希表实现的,哈希表是一种增删改查性能都较好的数据结构
目前的(jdk8+)哈希表是基于数组+链表+红黑树实现的。
我们可以肯定LinkedList的链能够一步增删元素的优势,但是却没法一步定位到元素,但是Hash可以逼近,Hash将元素的哈希值取余后的到的结果作为索引放入数组对应位置,如果多个元素位置相同就用链连接,这就是哈希表的雏形=数组+链表,虽然看起来漏洞百出。使用哈希表定位元素只需对哈希值取余得到索引,锁定数组位置,然后遍历链表,锁定元素。只需要保证哈希表取余和遍历都不会花上太多时间,那么哈希表在锁定元素上就也是成功的。
庆幸的是,哈希表的取余操作十分高效,这得益于它的设计,哈希表的数组长度保持为2的幂,用二进制数表示就是一个1+多个0,比如10=2,100=4,1000=8,那么对于随便一个二进制数,和这个2幂进行”按位与”运算就可以得到余数的二进制数。
如果我们保证一个数组位置上的元素不会太多,那么遍历链表也是开销极小的。哈希表默认的加载因子为0.75,意味着元素数超过数组长度*0.75时,哈希表会进行扩容,也就是将数组长度*2 ,这就保证了一个数组位置上的链表不会太长。此时又会产生一个问题,扩容后所有元素都需要重新取余计算位置吗?不用,哈希表也有巧妙的办法,基本上只需要移动一半的元素就可以。
同时,在红黑树的加持下,如果太过幸运,数组某位置上的链表过长(>8),那么哈希表会把这个链表变成红黑树,进一步为遍历加速。
因此,HashSet的性能是均衡地较好。
LinkedHashSet 就是在HashSet的基础上,给元素间加上了链,确定了它们的顺序。
TreeSet 底层不是哈希表了,而是红黑树,一种自平衡二叉树。性能感觉起来是更优雅的均衡较好。
随着元素数量增加,二叉树优势越为明显,如果数组+链表的结构能在低量元素时能比红黑树快,那么哈希表就比单纯的红黑树快。
Map Map和Set是一样的,更准确地说,Set底层用的就是Map,忽略了value只保留key而已。
其他问题 HashSet不能对内容一样的两个不同对象去重,为什么?怎么办? 比如自定义Student类
1 2 3 4 5 public class Student { private String name; private int age; private double height; }
1 2 Student s1 = new Student ("张三" , 22 , 189.5 );Student s2 = new Student ("张三" , 22 , 189.5 );
因为第一,哈希表需要对象的哈希值确定位置,而hashCode()默认是地址的比较,两个不同对象地址明显不同,使用哈希表会错误地把两个对象也放进去。解决办法是重写对象地hashCode()方法。
因为第二,如果两个对象hashCode()一致,在数组同一位置,此时会进行equals比较,如果是false,后者就会当作新元素。解决办法就是重写equals方法。
在Java中==对基本数据类型是值的比较,对对象是地址比较。
equals方法(一般不对基本数据类型比较),对对象是地址比较,但是对象的equals方法可以重写。这很常见,就像String一样是重写过的,使用equals实际上是在对值进行比较。
所以想要去重,就要重写对象的hashCode和equals方法。
idea可以快捷插入hashCode和equals,默认是值一样就相等。
1 2 3 4 5 6 7 8 9 10 11 12 @Override public boolean equals (Object o) { if (this == o) return true ; if (o == null || getClass() != o.getClass()) return false ; StudentComp student = (StudentComp) o; return age == student.age && Double.compare(height, student.height) == 0 && Objects.equals(name, student.name); } @Override public int hashCode () { return Objects.hash(name, age, height); }
如果TreeSet的键是自定义对象,怎么定义排序规则? 两个办法
Student类继承Comparable接口,重写compareTo方法
1 2 3 4 5 6 7 8 9 10 11 12 13 public class Student implements Comparable <Student> { private String name; @Override public int compareTo (Student o) { if (this .age!=o.age){ return Integer.compare(this .age, o.age); }else if (this .height!=o.height){ return Double.compare(this .height, o.height); }else { return this .name.compareTo(o.name); } } }
使用TreeSet时提供参数构造器的Comparator
1 2 3 4 5 6 7 8 9 10 11 12 Set<Student> set2 = new TreeSet <>(new Comparator <Student>() { @Override public int compare (Student o1, Student o2) { if (o1.age!=o2.age){ return Integer.compare(o1.age, o2.age); }else if (o1.height!=o2.height){ return Double.compare(o1.height, o2.height); }else { return o1.name.compareTo(o2.name); } } });
1 2 3 4 5 6 7 8 9 Set<Student> set2 = new TreeSet <>((o1, o2)->{ if (o1.age!=o2.age){ return Integer.compare(o1.age, o2.age); }else if (o1.height!=o2.height){ return Double.compare(o1.height, o2.height); }else { return o1.name.compareTo(o2.name); } });



















 https://www.bilibili.com/video/BV1Eh4y1R78n/?share_source=copy_web&vd_source=c049c0e0a94c93c0094803efaa8a12fc
https://www.bilibili.com/video/BV1Eh4y1R78n/?share_source=copy_web&vd_source=c049c0e0a94c93c0094803efaa8a12fc

 https://stackoverflow.com/questions/19335444/how-do-i-assign-a-port-mapping-to-an-existing-docker-container
https://stackoverflow.com/questions/19335444/how-do-i-assign-a-port-mapping-to-an-existing-docker-container