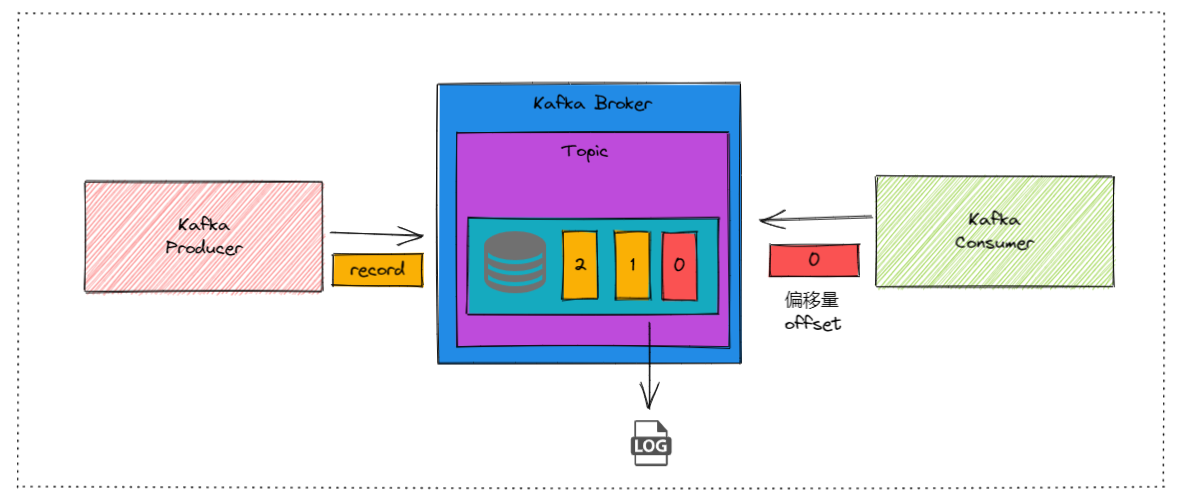
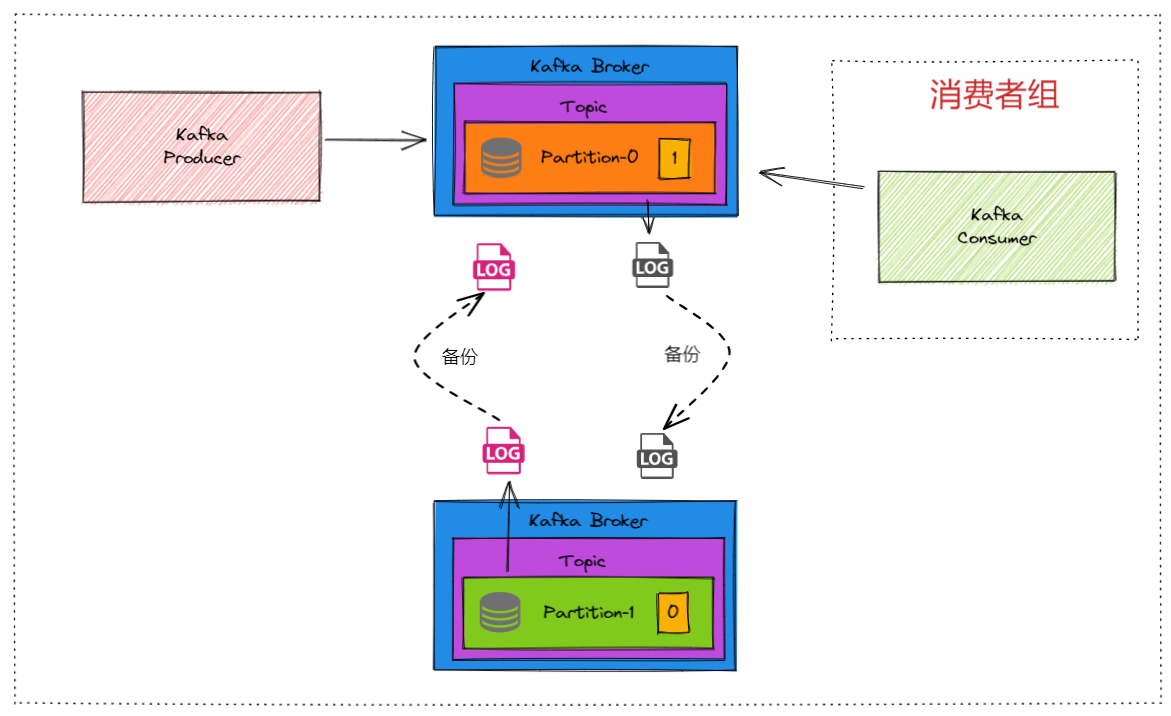
1. 安装、启动、连接 直接拿docker安装,拉取镜像,运行,开放端口。
1 docker pull nginx:stable-perl
虽然在容器中性能有所损失,但是方便,加快学习进度。
启动后浏览器访问localhost,写着Welcome等欢迎语,就是启动成功了。
在VSCode下载一些Docker常用插件,然后就可以拿VSCode直接连上’正在运行的容器’,和连接Linux服务器一样。
输入nginx -V,查看nginx信息,包括安装目录、编译参数、配置文件位置、日志文件位置等信息。可以看到配置文件位于--conf-path=/etc/nginx/nginx.conf 。
1 2 3 4 5 6 root@f4f6c922d837:/# nginx -V nginx version: nginx/1.26.1 built by gcc 12.2.0 (Debian 12.2.0-14) built with OpenSSL 3.0.11 19 Sep 2023 TLS SNI support enabled configure arguments: --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx.pid --lock-path=/var/run/nginx.lock --http-client-body-temp-path=/var/cache/nginx/client_temp --http-proxy-temp-path=/var/cache/nginx/proxy_temp --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp --http-scgi-temp-path=/var/cache/nginx/scgi_temp --user=nginx --group=nginx --with-compat --with-file-aio --with-threads --with-http_addition_module --with-http_auth_request_module --with-http_dav_module --with-http_flv_module --with-http_gunzip_module --with-http_gzip_static_module --with-http_mp4_module --with-http_random_index_module --with-http_realip_module --with-http_secure_link_module --with-http_slice_module --with-http_ssl_module --with-http_stub_status_module --with-http_sub_module --with-http_v2_module --with-http_v3_module --with-mail --with-mail_ssl_module --with-stream --with-stream_realip_module --with-stream_ssl_module --with-stream_ssl_preread_module --with-cc-opt='-g -O2 -ffile-prefix-map=/data/builder/debuild/nginx-1.26.1/debian/debuild-base/nginx-1.26.1=. -fstack-protector-strong -Wformat -Werror=format-security -Wp,-D_FORTIFY_SOURCE=2 -fPIC' --with-ld-opt='-Wl,-z,relro -Wl,-z,now -Wl,--as-needed -pie'
2. 快速尝试部署网站 查看nginx配置文件,可以找到如下部分。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 server { listen 80; listen [::]:80; server_name localhost; location / { root /usr/share/nginx/html; index index.html index.htm; } error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } }
这意味着,nginx 把所有对服务器根路径的请求,代理到 /usr/share/nginx/html 目录下,并且把 index.html 或 index.htm 作为默认页面。
如果你使用Vue或者Hex开发网站,它们的打包输出目录,大致结构分别如下
1 2 3 4 5 6 7 dist/ ├── css/ │ └── app.12345.css ├── js/ │ └── app.12345.js ├── index.html └── favicon.ico
1 2 3 4 5 6 7 8 9 10 public/ ├── css/ │ └── style.css ├── js/ │ └── script.js ├── index.html ├── about/ │ └── index.html └── archives/ └── index.html
你只需要把dist或者public下的所有文件,直接复制到/usr/share/nginx/html目录下,重启nginx即可。
3. 配置文件 这个版本的nginx自带2个配置文件,首先是nginx.conf。
如果你修改了配置文件,可以用nginx -t来校验配置是否合法。然后使用nginx -s reload来重新加载配置文件。
1. nginx.conf 全局配置 1 2 3 4 5 user nginx;worker_processes auto;error_log /var/log/nginx/error .log notice ;pid /var/run/nginx.pid;
user 指令
用法:user <username>;
描述:指定 Nginx 运行时使用的系统用户。
示例:user nginx; 表示使用 nginx 用户。
worker_processes 指令
用法:worker_processes <number|auto>;
描述:设置工作进程数,auto 会自动根据 CPU 核心数设置。
示例:worker_processes 4; 表示使用 4 个工作进程。
error_log 指令
用法:error_log <file> <level>;
描述:设置错误日志的路径和日志级别。
日志级别选项:
debug:调试信息info:一般信息notice:通知信息(默认)warn:警告信息error:错误信息crit:严重错误信息alert:需要立即处理的问题emerg:紧急情况
示例:error_log /var/log/nginx/error.log notice; 表示记录通知级别及以上的日志。
pid 指令
用法:pid <file>;
描述:指定存储 Nginx 进程 ID 的文件路径。
示例:pid /var/run/nginx.pid; 表示将 PID 存储在 /var/run/nginx.pid 文件中。
可能改动的部分:
worker_processes auto;
事件模块 1 2 3 events { worker_connections 1024 ; }
worker_connections 指令
用法:worker_connections <number>;
描述:设置每个工作进程允许的最大连接数。
示例:worker_connections 1024; 表示每个工作进程允许最多 1024 个连接。
可能改动的部分:
worker_connections 1024;
HTTP 模块 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local ] "$request " ' '$status $body_bytes_sent "$http_referer " ' '"$http_user_agent " "$http_x_forwarded_for "' ; access_log /var/log/nginx/access.log main; sendfile on ; keepalive_timeout 65 ; include /etc/nginx/conf.d/*.conf ; }
include 指令
用法:include <file|directory>;
描述:包含指定的文件或目录下的所有配置文件。
示例:include /etc/nginx/mime.types; 包含 MIME 类型配置文件。
default_type 指令
用法:default_type <MIME-type>;
描述:设置默认的 MIME 类型。
示例:default_type application/octet-stream; 表示未能确定文件类型时使用 application/octet-stream。
log_format 指令
access_log 指令
用法:access_log <file> <format>;
描述:设置访问日志的路径和日志格式。
示例:access_log /var/log/nginx/access.log main; 使用 main 格式记录访问日志。
sendfile 指令
用法:sendfile <on|off>;
描述:启用或禁用 sendfile 选项,用于提高文件传输效率。
示例:sendfile on; 启用 sendfile。
tcp_nopush 指令
用法:tcp_nopush <on|off>;
描述:用于优化传输数据时的 TCP 性能,通常与 sendfile 一起使用。
示例:#tcp_nopush on; 默认注释掉。
keepalive_timeout 指令
用法:keepalive_timeout <timeout>;
描述:设置保持客户端连接的超时时间,单位是秒。
示例:keepalive_timeout 65; 设置超时时间为 65 秒。
gzip 指令
用法:gzip <on|off>;
描述:启用或禁用 gzip 压缩。
示例:#gzip on; 默认注释掉。
include指令
用法:include <file|directory>;
描述:include 指令用于包含其他配置文件或目录中的所有配置文件。这可以帮助将配置文件分割成更小的部分,以便于管理和维护。
示例:include /etc/nginx/mime.types;:包含 MIME 类型配置文件。include /etc/nginx/conf.d/*.conf;:包含 /etc/nginx/conf.d/ 目录下的所有以 .conf 结尾的配置文件。
可能改动的部分:
keepalive_timeout 65;
默认设置为 65 秒,适用于大多数情况。
对于高并发的场景,可以适当调低以减少资源占用。
tcp_nopush on;
通常注释掉,如果启用,可以优化数据传输,尤其是在发送大文件时。
启用 tcp_nopush 后,Nginx 会尝试将数据块一次性发送到网络,而不是逐个包地发送,从而减少包的数量,提高传输效率。
通常与sendfile on;一起使用。启用 sendfile 后,数据在内核空间中直接从一个文件描述符传输到另一个文件描述符,避免了在用户空间和内核空间之间的多次拷贝,从而提高了传输效率。
gzip on;
通常开启后,可以启用 gzip 压缩以减少传输数据量,提高传输速度。
启用后还需配置 gzip_types 和其他参数,以确保正确压缩所需的文件类型。如
1 2 3 4 http { gzip on ; gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript; }
其他 gzip 配置选项 :
gzip_min_length:设置压缩的最小文件大小。gzip_comp_level:设置压缩级别(1-9),级别越高压缩率越大,但消耗的 CPU 资源更多。gzip_buffers:设置用于存储压缩结果的缓冲区大小。gzip_vary:设置 Vary: Accept-Encoding 响应头,指示代理服务器和浏览器缓存可以根据请求的 Accept-Encoding 头进行不同的缓存。
Gzip 压缩是通过压缩算法(如 DEFLATE)将 HTTP 响应内容压缩成更小的体积,然后再发送给客户端。解压缩的过程是nginx和浏览器自动完成的。
性能优化建议
**增加 worker_connections**:
提高每个工作进程的最大连接数可以显著提升 Nginx 的并发处理能力。
需要确保系统的文件描述符限制足够高。
启用 gzip 压缩 :
**优化 keepalive_timeout**:
在高并发情况下,适当调低 keepalive 超时时间以减少长时间占用连接资源。
**使用 tcp_nopush 和 tcp_nodelay**:
对于需要优化数据传输性能的场景,可以启用 tcp_nopush 和 tcp_nodelay。
2. default.conf 好的,让我们对 default.conf 文件的每一行进行解析:
server 块1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 server { listen 80 ; listen [::]:80 ; server_name localhost; location / { root /usr/share/nginx/html; index index.html index.htm; } error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } }
基本设置
**server { ... }**:
**listen 80;**:
监听 IPv4 的 80 端口,用于处理 HTTP 请求。
**listen [::]:80;**:
监听 IPv6 的 80 端口,用于处理 HTTP 请求。
**server_name localhost;**:
定义服务器的名称为 localhost,用于匹配请求的 Host 头。
日志设置
**#access_log /var/log/nginx/host.access.log main;**:
配置访问日志的路径和格式,此处被注释掉。如果启用,将使用 main 日志格式记录访问日志。
根路径设置
**location / { ... }**:
**root /usr/share/nginx/html;**:
指定请求的根目录为 /usr/share/nginx/html。
**index index.html index.htm;**:
指定默认的索引文件为 index.html 或 index.htm。
4. 反向代理 正向代理是代理客户端,客户端对于服务端来说是不可见的。
反向代理是代理服务端,服务端对于客户端来说是不可见的。
1. 模拟3个Web 1 docker pull python:3.9-slim
在桌面或任意地方新建app.py,内容为
1 2 3 4 5 6 7 8 9 10 11 12 from flask import Flaskimport osapp = Flask(__name__) @app.route('/' def hello (): return f"Hello from the backend server running on port {os.environ.get('PORT' )} !" if __name__ == "__main__" : app.run(host='0.0.0.0' , port=int (os.environ.get('PORT' , 5000 )))
启动3个python容器,模拟3个web服务。
1 2 3 4 5 6 7 8 C:\Users\mumu\Desktop>docker run --name web1 -d -e PORT=8081 -p 8081 :8081 -v /c/Users/mumu/Desktop/app.py:/app/app.py python:3.9 -slim sh -c "pip install flask && python /app/app.py" ab2ded77eafa82fbf4027f5714e5cb71bcb9775696f0e8c5423a70a7916a80ac C:\Users\mumu\Desktop>docker run --name web2 -d -e PORT=8082 -p 8082 :8082 -v /c/Users/mumu/Desktop/app.py:/app/app.py python:3.9 -slim sh -c "pip install flask && python /app/app.py" e6c5321ea3926157dc2f2d9ed38df53c715da51c496c5ff0e7ff0c4e68c85696 C:\Users\mumu\Desktop>docker run --name web3 -d -e PORT=8083 -p 8083 :8083 -v /c/Users/mumu/Desktop/app.py:/app/app.py python:3.9 -slim sh -c "pip install flask && python /app/app.py" f0bea8ac956af515fe35159fe94c86e919dfd566b782d06641472621a6299e26
需要保证nginx和3个python在同一个docker网络中,默认应该都是bridge。
2. 链接 使用docker inspect bridge查看刚才3个容器的ip。然后修改nginx的default.conf文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 upstream backend { server 172.17.0.3:8081 ; server 172.17.0.4:8082 ; server 172.17.0.5:8083 ; } server { listen 80 ; listen [::]:80 ; server_name localhost; location / { root /usr/share/nginx/html; index index.html index.htm; } location /app { proxy_pass http://backend/; } error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } }
**proxy_pass http://backend/;**:将这些请求代理到上游服务器组 backend。请求的路径 /app 的前缀将被去除,然后传递给上游服务器。例如,/app/foo 将被代理为 /foo。
重启服务。
访问localhost/app并多次刷新试试。
5. 负载均衡 在不断刷新页面会发现,反向代理是以“轮询”的方式,将请求分发到3个web服务之一的。
除了轮询之外,还有以下方式。
1. 加权轮询,Weighted Round Robin 可以为不同的服务器设置权重,权重越高,服务器被请求的概率越大。
1 2 3 4 5 upstream backend { server 172.17.0.3:8081 weight=3 ; server 172.17.0.4:8082 weight=2 ; server 172.17.0.5:8083 weight=1 ; }
weight默认为1 。
2. 最少连接,Least Connections 将请求分发给当前连接数最少的服务器,适用于处理时间长、连接占用多的请求。
1 2 3 4 5 6 upstream backend { least_conn; server 172.17.0.3:8081 ; server 172.17.0.4:8082 ; server 172.17.0.5:8083 ; }
3. IP哈希,IP Hash 根据客户端 IP 地址进行哈希计算,保证同一客户端的请求总是转发到同一台服务器,适用于会话保持。
1 2 3 4 5 6 upstream backend { ip_hash; server 172.17.0.3:8081 ; server 172.17.0.4:8082 ; server 172.17.0.5:8083 ; }
4. 哈希,Hash 根据自定义的键值进行哈希计算来分发请求。
1 2 3 4 5 6 upstream backend { hash $request_uri ; server 172.17.0.3:8081 ; server 172.17.0.4:8082 ; server 172.17.0.5:8083 ; }
可以使用以下变量作为键值:
$remote_addr:客户端 IP 地址$request_uri:请求的 URI$http_cookie:请求的 Cookie
ip_hash和hash $remote_addr一样都可以实现同一个客户端的请求分配到同一个后端服务器。但是一般这种情况使用前者更多。
6. HTTPS 首先要安装有openssl,然后创建一个存放证书和私钥的文件夹,比如mkdir C:\nginx\ssl
执行
1 openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout C:\nginx\ssl\nginx-selfsigned.key -out C:\nginx\ssl\nginx-selfsigned.crt
按问题填写信息,就可以。
得到2个文件后,复制到容器中,比如/etc/nginx/ssl目录下,然后再default.conf中添加一个server块,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 server { listen 443 ssl; listen [::]:443 ssl; server_name localhost; ssl_certificate /etc/nginx/ssl/nginx-selfsigned.crt; ssl_certificate_key /etc/nginx/ssl/nginx-selfsigned.key; location / { root /usr/share/nginx/html; index index.html index.htm; } location /app { proxy_pass http://backend/; } error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } }
打开浏览器访问https://localhost
7. 虚拟主机 一个server块就是一个虚拟主机。
新建一个conf文件和default.conf同一目录。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 upstream backend2 { server 172.17.0.3:8081 weight=2 ; server 172.17.0.4:8082 weight=2 ; server 172.17.0.5:8083 weight=6 ; } server { listen 81 ; listen [::]:81 ; server_name localhost; location / { root /usr/share/nginx/html; index index.html index.htm; } location /app { proxy_pass http://backend2/; } error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } }
重启服务,浏览器访问http://localhost:81/app 。
利用这种方式,我们可以在同一台机器上部署多个网站。