
csdnToMD
项目原作者:https://gitee.com/liushili888/csdn-is---mark-down
改进后仓库地址:https://github.com/Xiamu-ssr/csdnToMD
改进
这里进行一定的改进,可以更准确获取时间,也可以选择图片的存放方式是否集中或分离到每篇文章的同名文件夹,以适应部分md扩展语法,比如{% asset_img 1.png %}
爬取结果截图
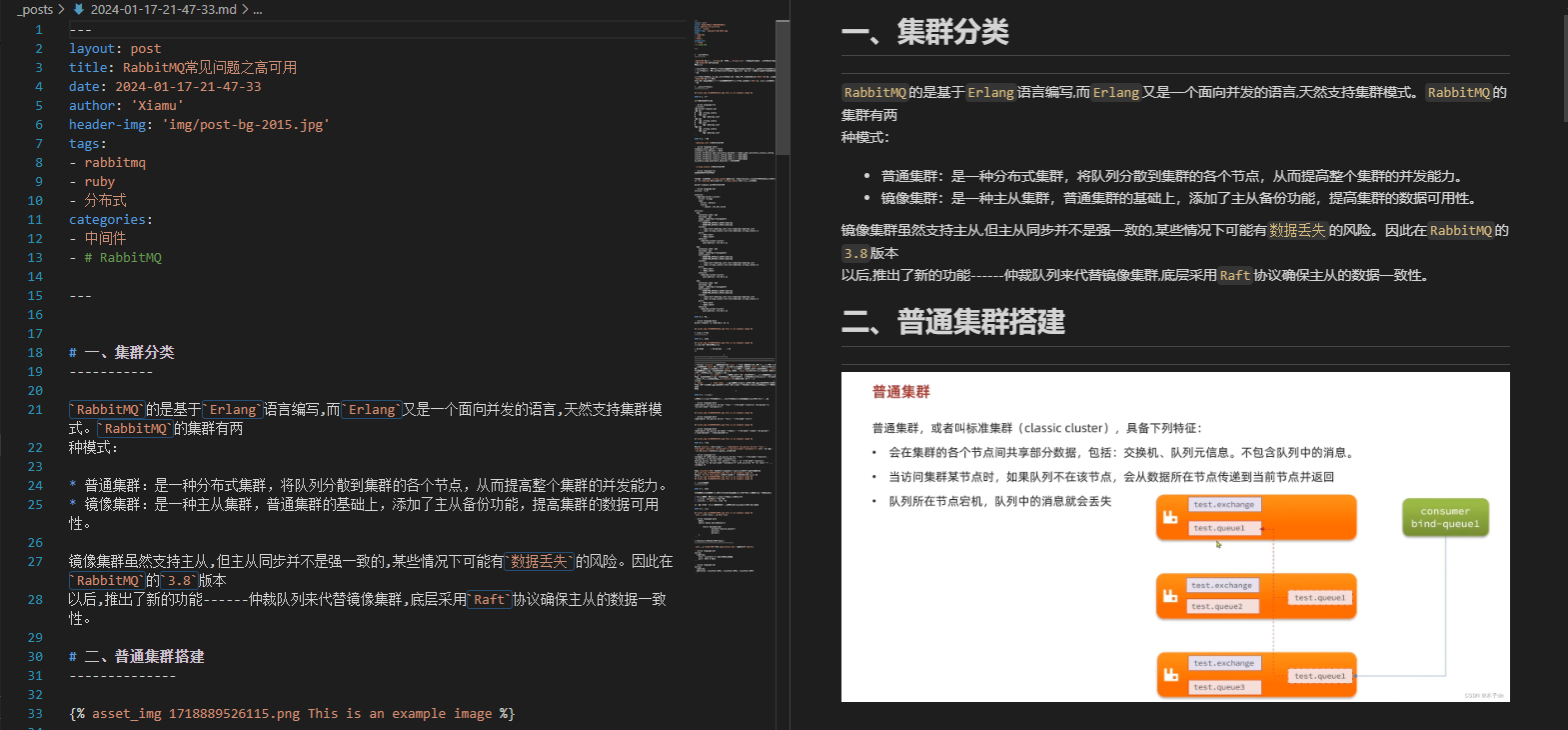
将CSDN文章转化为Markdown文档
很多情况下,我们需要将CSDN中的文章转化为markdown文档,直接复制全文是不可以的,CSDN不支持。
那有什么办法快速得到md文档?
原理:
- 由于CSDN不是获取数据不是前后端分离的,所以无法根据接口获取文章的所有数据,它的数据是和页面元素组合在一起的,需要根据页面中的元素标签转化为markdown中的元素标签。
- 使用jsoup解析csdn文档
- 利用
jericho-html、flexmark-all、jsoup、selenium等工具将html文档转化为markdown文档
使用:
- 去
https://googlechromelabs.github.io/chrome-for-testing/下载chromedriver,解压后修改DynamicScraperTime函数的驱动地址。如果不下载驱动也可以,把String time = DynamicScraperTime(startUrl);的获取换成下一行被注释的就行,但是因为页面动态加载的原因,会无法获取准确的时间。 - 然后直接将CSDN文章的url放入
crawler类即可
例如:
获取单个文章markdown
1 | public class Main { |
获取所有的文章markdown
1 | public class Main { |
项目中待解决的问题
TODO ‘> ’标签中包含代码块,需要处理TODO 代码中格式待处理TODO 增加GUI页面TODO 公式、表格标签的处理



