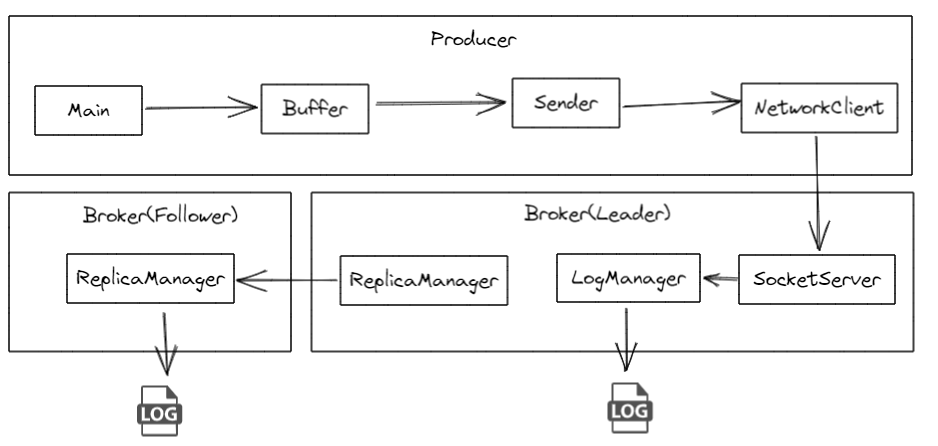
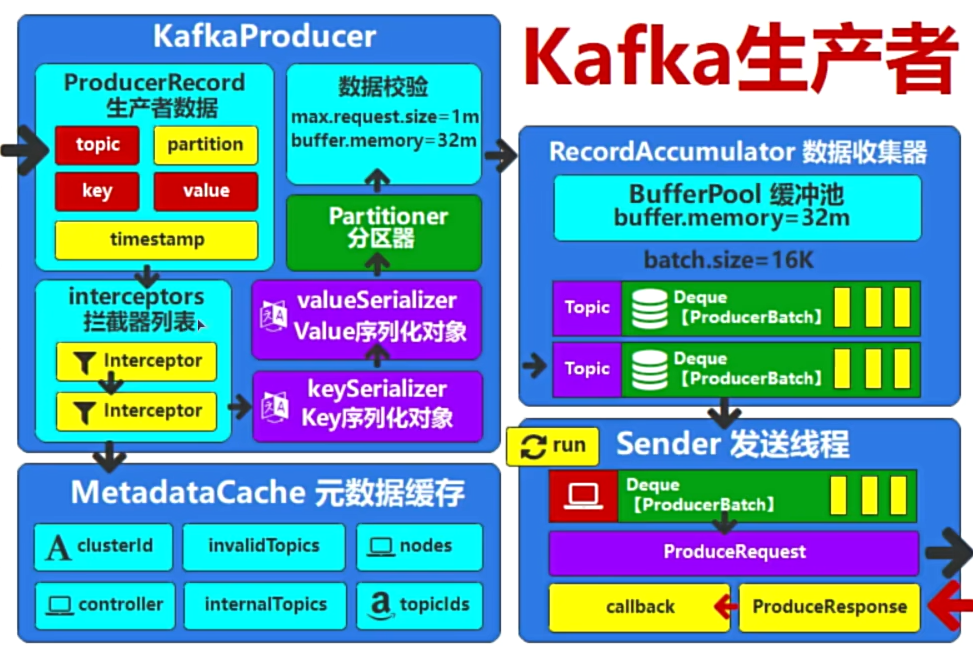
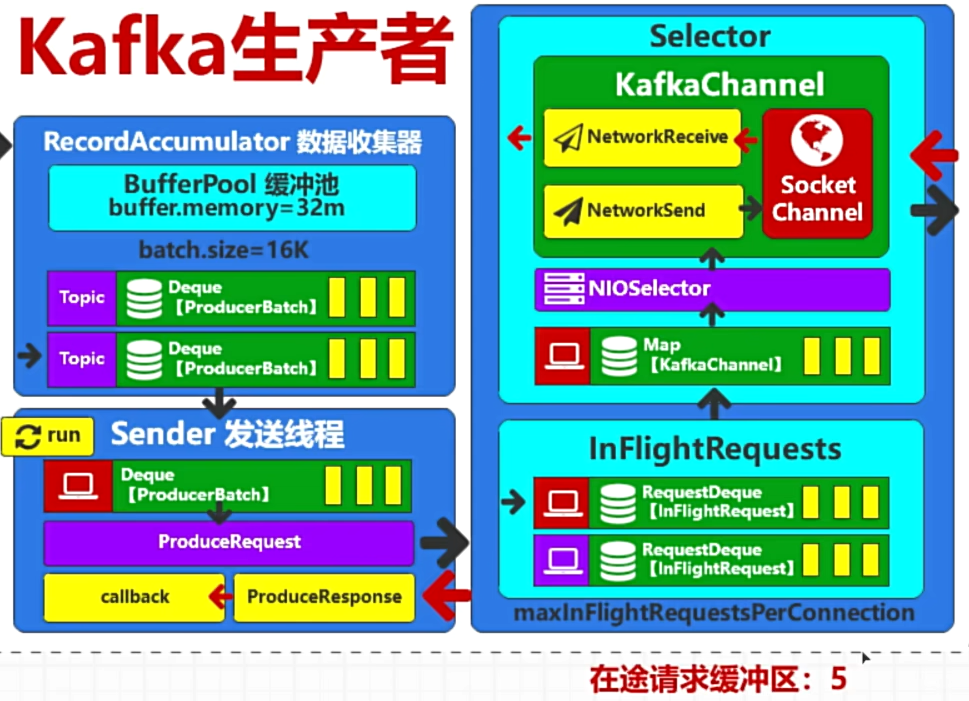
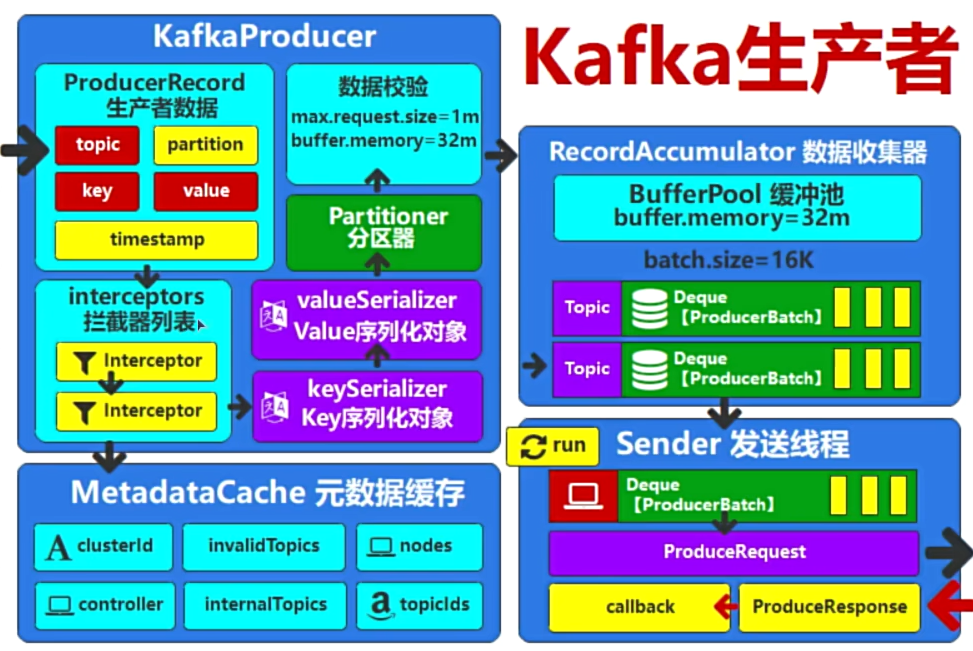
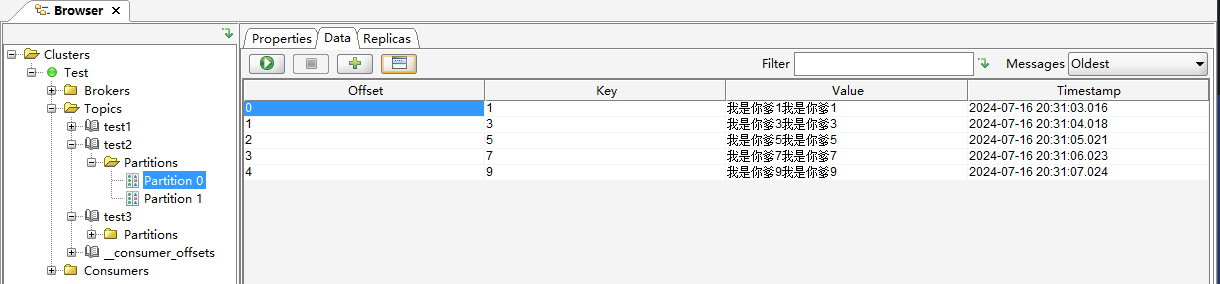
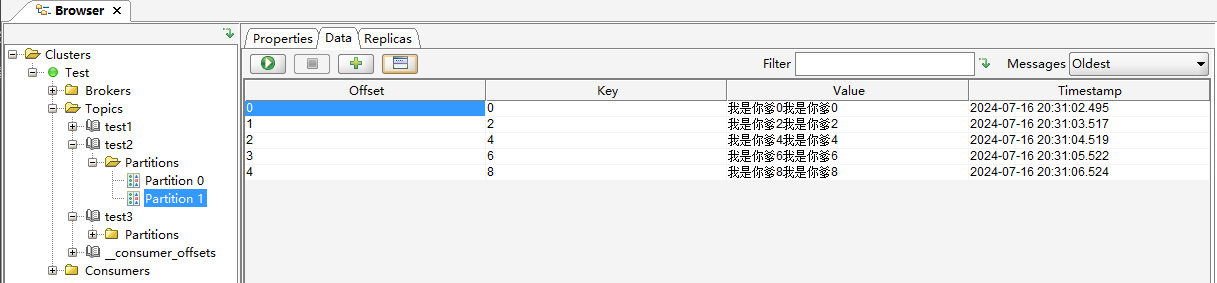
publicclassMyKafkaPartitionerimplementsPartitioner { @Override publicintpartition(String s, Object key, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) { // Ensure the key is a non-null string if (key == null || !(key instanceof String)) { thrownewIllegalArgumentException("Key must be a non-null String"); }
// Parse the key as an integer int keyInt; try { keyInt = Integer.parseInt((String) key); } catch (NumberFormatException e) { thrownewIllegalArgumentException("Key must be a numeric string", e); }
// Determine the partition based on the key's odd/even nature if (keyInt % 2 == 0) { return1; // Even keys go to partition 2 } else { return0; // Odd keys go to partition 0 } }